一、数据库系统基础
1、数据库及系统基本概念
数据模型是一种描述事务对象数据特征及其结构的形式化表示,通常由数据结构、数据操作、数据约束三个部分组成
- 数据结构用于描述事物对象的静态特征
- 数据操作用于描述事物对象的动态特征
- 数据约束用于描述事物对象的数据之间语义的联系
传统数据模型:
- 层次数据模型——“树结构”
- 网状数据模型——“图结构”
- 关系数据模型——“关系二维表”
数据库系统由用户、数据库应用程序、数据库管理程序和数据库四个部分组成
2、数据库技术发展
- 人工数据管理阶段
- 文件系统管理阶段
- 数据库管理阶段
发展时代
- 20世纪60年代末出现的层次模型数据库技术和网状数据模型
- 20世纪70年代出现的关系模型数据库技术
- 20世纪90年代出现的面向对象数据库技术和对象-关系数据库技术
- 本世纪初期出现的半结构化数据库技术,以及当今面向互联网应用的非结构化数据库技术、大规模分布式数据库技术
3、数据库应用系统
数据库应用系统类型
- 业务处理系统
- 管理信息系统
- 决策支持系统
数据库应用系统结构
- 单用户结构
- 集中式结构
- 客户/服务器结构
- 分布式结构
数据库应用系统的生命周期
- 系统需求分析
- 系统设计
- 系统实现
- 系统测试
- 系统运行与维护
4、典型数据库管理系统
- Microsoft SQL Server
- Oracle Database
- Mysql
- Postgresql
5、PostgreSQL
数据库对象
- schema
- 表
- 视图
- 序列
- 函数
- 触发器
二、数据库关系模型
1、关系及其相关概念
实体:指包含数据特征的事物对象在概念模型世界中的抽象名称
关系模型:一种采用关系二维表的数据结构形式存储实体及其实体间联系的数据模型
关系键定义:
- 复合键
- 候选键
- 主键
2、关系模型原理
数据结构、操作方式、数据约束
模型操作:
(1)传统集合运算
- 并运算
- 差运算
- 交运算
- 广义笛卡尔积
(2)专门关系运算
选择运算
投影运算
连接运算
- θ连接
- 自然连接
- 外连接
- 左外连接
- 右外连接
- 全外连接
除运算
数据完整性约束:
实体完整性——主键唯一非空性
参照完整性——主外键一致性、级联更新、级联删除
用户自定义完整性
三、数据库操作语言SQL
类型
- 数据定义语言(Data Definition Language ,DDL)
- 数据操纵语言(Data Manipulation Language,DML)
- 数据查询语言(Data Query Language,DQL)
- 数据控制语言(Data Control Language,DCL)
- 事务处理语言(Transaction Process Language,TPL)
- 游标控制语言(Cursor Control Language,CCL)
DDL
CREATE DATABASE <数据库表名>;
ALTER DATABASE <数据库名> [[WITH] option [...]];
DROP DATABASE <数据库名>;CREATE TABLE <表名>
(
<列名1> <数据类型> [列完整性约束];
<列名2> <数据类型> [列完整性约束];
<列名3> <数据类型> [列完整性约束];
...
)
ALTER TABLE <表名> <修改方式>;
DROP TABLE <表名>;DML
INSERT INTO <基本表>[<列名表>] VALUES(列值表);
UPDATE <基本表> SET <列名1>=<表达式1> [,<列名2>=<表达式2>...] [WHERE <条件表达式>];
DELETE FROM <表名> [WHERE <条件表达式>];DQL
SELECT [ALL|DISTINCT] <(内置函数)目标列>[,<目标列>...] AS [别名]
[INTO <新表> ]
FROM <表名>[,<表名>..]
[WHERE <条件表达式(LIKE)>[AND/OR]... ]/[[LEFT/RIGHT/ALL]JOIN <表名> AS <别名> ON <条件表达式>]
[GROUP BY <列名> [HAVING <条件表达式>]]
[ORDER BY <列名> [ASC | DESC]];- DISTINCT 关键字过滤重复元组
- 通配符 ‘_’表示一个字符 ‘%’表示一个或多个字符
- 默认ORDER BY 为升序
- 内连接:只有关联表相关字段的列值满足等值连接条件时,这些关联表中提取数据组合成新的数据集
- 外连接:
- 左外连接:即使右表没有匹配,也从左表返回所有的行
- 右外连接:即使左表没有匹配,也从右表返回所有的行
- 全外连接:只要其中一个表中存在匹配,就返回行
DCL
GRANT <权限列表> ON <数据库对象> TO <用户或角色> [WITH GRANT OPTION];
REVOKE <权限列表> ON <数据库对象> FROM <用户或列表>;
DENY <权限列表> ON <数据库对象> TO <用户或角色> //用于防止用户或角色通过其组或角色成员继承权限权限列表:SELECT、INSERT、UPDATE、DELETE
VIEW视图
CREATE VIEW <视图名>[(列名1),(列名2),...] AS <SELECT 查询>;
DROP VIEW <视图名>;视图通过虚拟视窗映射到基础表中的数据
视图的好处:
- 简化复杂SQL查询操作
- 提高数据访问安全性
- 提供一定程度的数据逻辑独立性
- 集中展示用户所感兴趣的特定数据
四、数据库设计与实现
1、数据库的设计概念
数据库设计方案
- 概念数据模型(Conceptual Data Mode ,CDM)
- 逻辑数据模型(Logic Data Mode,LDM)
- 物理数据模型(Physical Data Model, PDM)
| 概念数据模型 | 逻辑数据模型 | 物理数据模型 |
|---|---|---|
| 实体 | 实体 | 表 |
| 属性 | 属性 | 列 |
| 标识符 | 标识符 | 键 |
| 联系 | 联系 | 参照完整性约束 |
数据库设计策略
- 自底向上策略:适合规模小、业务数据简单的数据库设计
- 自顶向下策略:适合规模大、业务数据关系错综复杂的数据库设计
- 由内至外策略:自底向上的特例
- 混合设计策略
2、E-R模型
实体-联系模型
- 实体
- 属性:唯一标识不同实体或实例的称为标识符
- 联系
实体间联系分类
- 多重性分类
- 一对一分类
- 一对多分类
- 多对多分类
- 参与性分类
- 继承性分类
- 非互斥继承
- 互斥继承
- 完整继承
- 非完整继承


强弱实体
某些实体对另一些实体有逻辑上的依赖联系,即一个实体的存在必须以另一个实体的存在为前提,前者就被称为弱实体,而被依赖的实体被称为强实体
弱实体又被分为标识符依赖弱实体和非标识符依赖弱实体
- 标识符依赖弱实体:弱实体的标识符含有所依赖实体的标识符
- 非标识符依赖弱实体:有自己的标识符
对标识符依赖弱实体的联系连线图形符号,在弱实体的一侧有一个三角形的符号
对非标识符依赖弱实体的联系连线图形符号,在弱实体的一侧仅为基本鸟足符号
3、数据库建模设计
概念数据模型
- 抽取与标识实体
- 分析与标识实体联系
- 定义实体属性与标识符
- 检查与完善数据模型
逻辑数据模型
- CDM/LDM转换
- 规范化与完善数据模型设计
物理数据模型设计
实体到关系表的转换
- 代理键设置
- 列特性设置
- 空值状态
- 默认值
- 数据约束
弱实体到关系表的切换
- 非标识依赖:在弱实体转换的关系表中加入强实体标识符作为外键列
- 标识符依赖:不仅在弱实体转换的关系表中加入强实体标识符作为外键列,同时也作为该表的主键列
实体联系的切换
- 1:1实体联系转换:将一个表的主键放到另一个表中当外键
- 1:N实体联系转换:将1端关系表的主键放到N端关系表中作为外键
- M:N实体联系转换:增加一个关系表,作为关系表与实体的关系建立参照约束
- 实体继承关系的转换:父表属性放到子表中作为外键
- 实体递归关系的转换:(1:N) 在表中加入另一个外键属性参照本表主键属性 (M:N)派生出一个新的关联表,其表名是联系的名称
4、数据库规范化设计
数据冗余指一组数据重复出现在数据库的多个表中。在数据库表设计中,我们应尽量避免表间的重复数据列。
非规范化关系表的问题
- 插入数据异常
- 删除数据异常
- 修改数据异常
函数依赖理论
- 平凡函数依赖
- 部分函数依赖
- 传递函数依赖
- 多值依赖
规范化设计范式
第一范式
关系表的属性列不能重复,并且每个属性列都是不可分割的基本数据项
第二范式
(消除部分函数依赖)
满足第一范式,且关系表中所有数据都要和该关系表的主键有完全函数依赖
第三范式
(消除传递函数依赖)
满足第二范式,且所有非主键属性均不存在传递函数依赖
巴斯-科德(BCNF)范式
满足第三范式,且所有函数依赖的决定因子必须是候选键
第四范式
满足BCNF范式,且消除了多值依赖
第五范式
如果一个关系为消除其中连接依赖,进行投影分解,所分解的各个关系均包含原关系的一个候选键,则这些分解后的关系满足第五范式
逆规范化处理
- 关系表的合并
- 冗余列的增加
- 抽取表的创建
- 关系表分区的创建
五、数据库管理
1、数据库管理的目标与内容
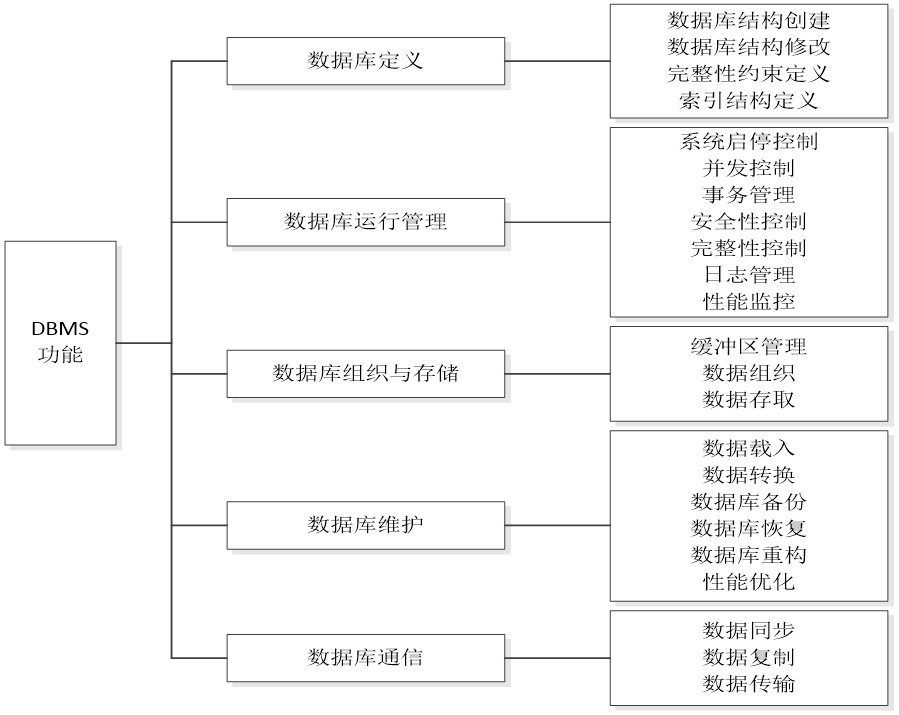
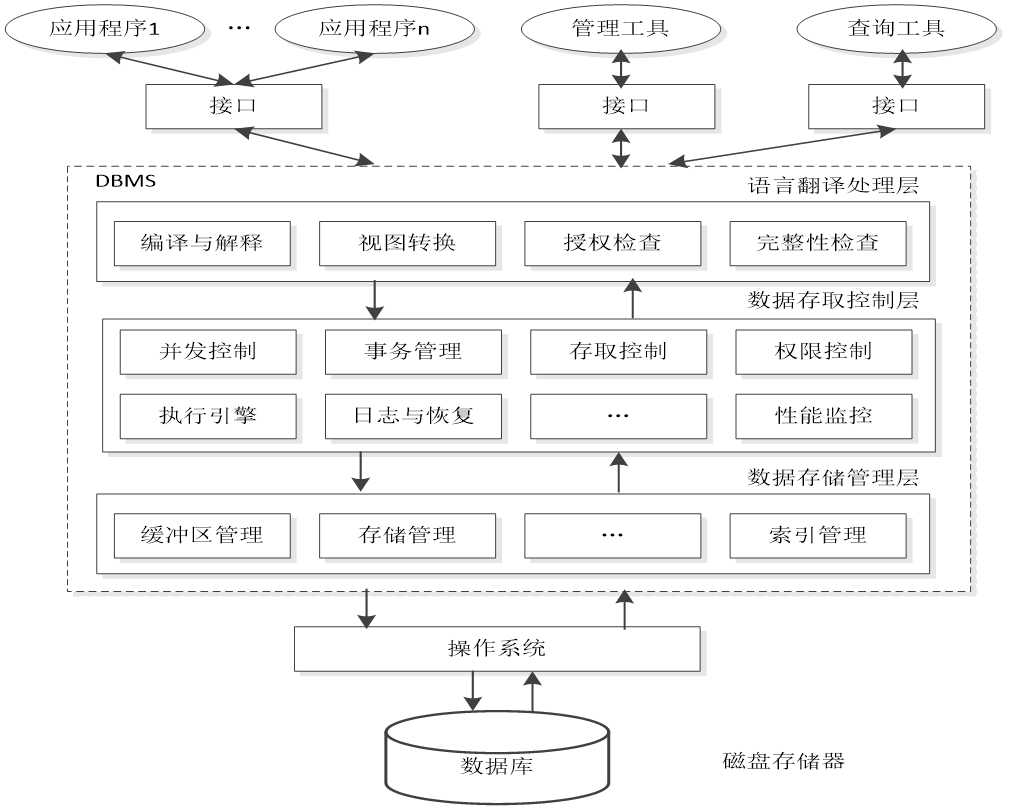
2、事务管理
事务:由构成单个逻辑处理单元的一组数据库访问操作,这些操作的SQL语句被封装在一起,要么都被执行,要么都不执行
- 事务是DBMS执行的最小任务单元
- 事务是DBMS最小的故障恢复任务单元
- 事务是DBMS最小的并发控制任务单元
事务特性:ACID原则
(1)原子性:Atomicity
事务中SQL语句对数据的修改操作,要么全都被正确执行,要么全都不被正确执行
(2)一致性:Consistency
事务执行的结果使数据库从一种正确数据状态变迁到另一种正确数据状态
(3)隔离性:Isolation
多个事务并发执行时,一个事务的执行不能被其他事务干扰,即另一个事务对数据所做的修改对其他并发事务是隔离的,各个并发事务之间不能相互影响
(4)持续性:Durability
事务持续性指一个事务一旦提交,它对数据中数据的改变应该是永久性的
并发执行事务好处:
- 改善系统的资源利用率
- 减少事务执行的平均等待时间
事务SQL语句
BEGIN;
SQL 语句1;
SQL 语句2;
...
SQL 语句n;
COMMIT;或ROLLBACK3、并发控制
(1)脏读
多个事务并发运行,并操作访问共享数据,其中一个事务读取了被另一个事务所修改所修改后的共享数据,但修改数据的事务因某种原因失败,数据未被提交到数据库文件,而读取共享数据的事务则读取得到一个垃圾数据,即脏数据。
脏数据——对未提交的修改数据的统称
(2)不可重复读
不可重复读指一个事务对同一共享数据先后重复读取两次,但是发现原有数据改变或丢失。
原因——多个事务并发运行时,一些事务对共享数据进行多次读操作,但其中一个事务对共享数据进行了修改或删除操作
(3)幻想读
幻想读指一个事务对同一共享数据重复读取两次,但是发现第2次读取比第1次读取的结果中新增了一些数据
原因——多个事务并发运行,其中一个事务同时在对共享数据进行添加操作
(4)丢失更新
一个事务对一共享数据进行更新处理,但是以后查询该共享数据值时,发现该数据与自己的更新值不一致
原因——多个事务并发执行,其中一个事务对共享数据进行了更新,并改变了前面事务的更新值
并发事务调度
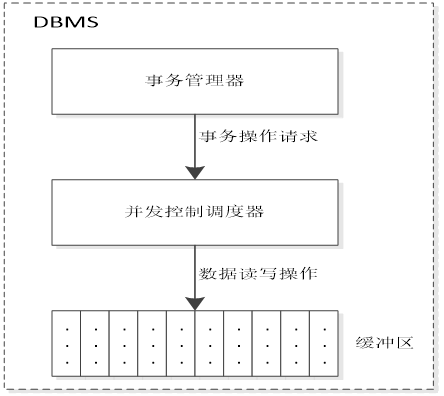
在DBMS中,事务管理器将并发执行事务的SQL数据操作请求提交给并发控制调度器。由并发控制调度器将各个事务的SQL数据操作请求按照一定顺序进行调度执行,并完成对数据库缓冲区的读写操作。
在事务并发执行中,只有当事务中数据操作调度顺序的执行结果与事务串行执行结果一样时,该并发事务调度才能保证数据操作的正确性和一致性。符合这样效果的调度称为可串行化调度。
数据库锁机制
锁机制与并发控制调度器结合,实现共享资源的锁定访问
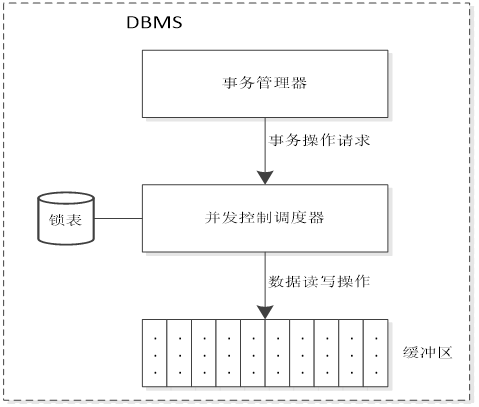
排它锁定(Lock-X)——又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再加锁读取和修改A。
共享锁定(Lock-S)——又称读锁。若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
基于锁的并发控制协议
事务可串行化调度是确保数据库一致性的基本方法
(1)锁操作相容性
| 类型 | 排他锁 | 共享锁 | 无锁 |
|---|---|---|---|
| 排他锁 | 否 | 否 | 是 |
| 共享锁 | 否 | 是 | 是 |
| 无锁 | 是 | 是 | 是 |
(2)加锁协议
1、一级加锁协议
任何事务在修改共享数据对象之前,必须对该数据执行排它锁定指令,直到该事务处理完成,才进行解锁指令执行。
防止“丢失更新”不一致问题
2、二级加锁协议
在一级加锁协议基础上,针对并发事务的共享数据读操作,必须对该数据执行共享锁定指令,读完数据后即刻释放共享锁定。
防止出现“丢失更新”不一致问题,“脏数据“问题
3、三级加锁协议
在一级加锁协议基础上,针对并发事务对共享数据进行读操作,必须对该数据执行共享锁定指令,直到该事务处理结束才释放共享锁定。
防止出现“丢失更新”不一致问题,“脏数据“问题,“不可重复读”问题
| 加锁协议级别 | 排它锁 | 共享锁 | 不丢失更新 | 不脏读 | 可重复读 |
|---|---|---|---|---|---|
| 一级 | 全程加锁 | 不加 | 是 | 否 | 否 |
| 二级 | 全程加锁 | 开始时加锁,读完数据释放锁定 | 是 | 是 | 否 |
| 三级 | 全程加锁 | 全程加锁 | 是 | 是 | 是 |
两阶段锁定协议
并发事务的正确调度准则:
一个给定的并发事务调度,当且仅当它是可串行化时,才能保证正确调度。
保证可串行化的一个协议是:二阶段锁定协议
二阶段锁定协议规定每个事务必须分两个阶段提出加锁和解锁申请:
- 增长阶段,事务只能获得锁,但不能释放锁。
- 缩减阶段,事务只能释放锁,但不能获得新锁。
并发事务死锁解决
死锁必要条件:
(1)互斥条件
(2)请求和保持条件
(3)不剥夺条件
(4)环路等待条件
解决死锁问题的两类策略:
(1)在并发事务执行时,预防死锁
(2)在死锁出现后,其中一个事务释放资源以解除死锁
事务隔离级别

事务隔离级别设置是在DBMS中执行SET TRANSACTION命令来实现或通过管理工具设置。事务隔离级别设置越高,出现数据不一致的可能性越小,但系统吞吐量也越小。
4、安全管理
数据库安全模型

用户管理
用户创建
CREATE USER <用户账号名> [ [WITH] option [...]];用户修改
ALTER USER <用户名> [[WITH] option [...]];用户删除
DROP USER <用户名>;权限管理
(1)权限类别
- 数据库对象访问操作权限
- 数据库对象定义操作权限
(2)权限管理
- 执行sql控制语句进行权限管理
- 运行数据库管理工具进行权限管理
角色管理
CREATE ROLE [角色名] [[WITH] option [...]];
ALTER ROLE [角色名] [[WITH] option [...]];
DROP ROLE <角色名>5、备份与恢复
备份方式
- 完整数据库备份
- 差异数据库备份
- 事务日志备份
- 文件备份
又分为 热备份 与 冷备份
备份设备
- 磁盘阵列
- 磁带库
- 光盘库
备份方法
- 使用实用程序工具进行数据库备份
pg_dump [连接选项] [一般选项] [输出控制选项] 数据库名称pg_dumpall [连接选项] [一般选项] [输出控制选项]
- 使用管理工具GUI操作进行备份
备份恢复
- 使用实用程序工具恢复数据库备份
psql [连接选项] -d 恢复的数据库 -f 备份文件——对应pg_dumppg_restore [连接选项] [一般选项] [恢复控制选项] 备份文件——对应pg_dumpall
- 使用管理工具GUI操作恢复数据库备份
六、数据库应用编程
1、JDBC
Class.forName("org.postgresql.Driver");
Connection conn = DriverManager.getConnection(url,user,password);
Statement st = (Statement)conn.createStatement;
ResultSet rs = st.excuteQuery(sql);
while(rs.next()){
String result = rs.getString("xxx");
...
System.out.println(result...)
}2、MyBatis
三层功能框架
- API接口层
- 数据处理层
- 基础支撑层
访问数据库的基本过程
- 读取配置文件SqlMapConfig.xml,此文件作为MyBatis的全局配置文件,配置了MyBatis的运行环境等信息
- SqlSessionFactoryBuilder通过Configuration生成sqlSessionFactory对象
- 通过sqlSessionFactory打开一个数据库会话sqlSession,操作数据库需要通过sqlSession进行
- MyBatis底层自定义了Executor执行器接口操作数据库,Executor接口负责动态SQL的生成和查询缓存的维护,将MappedStatement对象进行解析,sql参数转化,动态SQL拼接,生成JDBC Statement对象,通过Satement进行输入和输出
3、存储过程编程
存储过程是一种数据库的对象,由一组能完成特定功能的SQL语句集构成。它把经常会被重复使用的SQL语句逻辑块封装起来,经编译后,存储在数据库服务器端,它被再次调用时,不需要再次编译;当客户端连接到数据库时,用户通过指定存储过程的名称并给出参数,数据库就可以找到相应的存储过程并予以调用。
创建存储过程
CREATE [OR REPLACE] FUNCTION
Name ( [ [argmode] [argname] argtype [ {DEFAULT | = } default_expr ] [,...] ] )
[ RETURNS retype | RETURNS TABLE ( column_name column_type [, ...] ) ]
AS $
DECLARE
--声明段
BEGIN
--函数体语句
END;
$$ LANGUAGE lang_name;- OR REPLACE:如果没有该名称,则创建存储过程
- argmode:参数:IN、OUT、INOUT
- argname:形式参数名称
- argtype:该函数值的返回类型
- default_expr:指定参数默认值的表达式。该表达式的类型必须是可转化为参数的类型
- retype:指示RETURNS返回值的数据类型
- RETURNS TABLE:指示存储过程返回值的类型是由多列构成的二维表
- AS $$:声明存储过程代码的开始
- DECLARE:指示声明存储过程的局部变量
- BEGIN…END:定义存储过程的执行体语句
- LANGUAGE:指明存储过程使用的编程语言
删除存储过程
DROP FUNCTION [ IF EXISTS ] name ( [ [ argmode ] [ argname ] argtype [, ...] ] )
[ CASCADE | RESTRICT ]- CASCADE:级联删除依赖于函数的对象(如操作符或触发器)
- RESTRICT:如果有任何依赖对象存在,则拒绝删除该函数;这个是默认值
4、触发器编程
触发器是在某个事件发生时自动地隐式运行
创建触发器
CREATE [CONSTRAINT] TRIGGER name
{ BEFORE | ALTER | INSTEAD OF } { event [ OR ...] }
ON table_name
[ FROM referenced_table_name ]
[ FOR [ EACH ] { ROW | STATEMENT } ]
[ WHEN (condition) ]
EXECUTE PROCEDURE function_name ( arguments )- table_name:触发器所作用的表
- referenced_table_name:主要用于有外键约束的两张表
- function_name:用户提供的函数名
分类
根据执行次数
1、语句级触发器
关键字FOR EACH STATEMENT声明,在触发器作用的表上执行一条SQL语句时,该触发器只执行一次,即使修改了零行数据的SQL,也会导致相应的触发器执行
2、行级触发器
关键字FOR EACH ROW标记,当特定事件导致触发器作用的表的数据发生变化时,每变化一行就会执行一次触发器。
根据引发的时间
1、BEFORE触发器
事件前
2、AFTER触发器
事件后
3、INSTEAD OF 触发器
当触发事件发生后,数据库管理系统不执行引起事件触发的SQL语句,而执行相应触发器的函数,这类触发器通常定义在视图上
特殊变量
- NEW:record,该变量为行级触发器中的INSERT/UPDATE操作,保存在新数据行
- OLD:record,该变量为行级触发器中的UPDATE/DELETE操作,保存在旧数据行
- TG_NAME:name,该变量包含实际触发的触发器名称
- TG_WHEN:text,值为BEFORE、AFTER或INSTEAD OF的一个字符串,取决于触发器的定义
- TG_LEVEL:text,值为ROW、STATEMENT的一个字符串,取决于触发器的定义
- TG_OP:text,值为INSERT、UPDTAE、TRUNCATE的一个字符串,它说明触发器由哪个操作引发
- TG_RELID:old,引发触发器调用的表的对象的ID
- TG_RELNAME:name,导致触发器调用的表的名称(将被废弃)
- TG_TABLE_NAME:name,导致触发器调用的表的名称
- TG_TABLE_SCHEMA:name,触发器调用的表的模式名称
- TG_NARGS:integer,在CREATE TRIGGER语句中给触发器过程的参数数量
- TG_ARGV[]:text数组,来自CREATE TRIGGER语句的参数。
删除触发器
DROP TRIGGER [ IF EXISTS ] name ON table_name [ CASCADE | RESTRICT ]5、事件触发器
针对一个特定的数据库的全局触发器,并且可以捕获DDL事件
三类:
- ddl_command_start:在DDL开始前触发、
- ddl_command_end:在DDL结束后触发
- sql_drop:删除一个数据库对象前被触发,删除的数据库对象的详细信息,可以通过pg_event_trigger_dropped_objects()函数记录下来
创建事件触发器
CREATE EVENT TRIGGER name
ON event
[ WHEN filter_variable IN (filter_value [,...]) [ AND ... ] ]
EXECUTE PROCEDURE function_name();- name:定义的新触发器的名称
- event:触发调用的触发器函数的名称
- filter_variable:筛选事件的变量名称,指定它所支持的触发该触发器的时间子集
- filter_value:可以触发该触发器的filter_variable的值,相关TAG所限定的命令列表
- function_name:用户声明的不带参数的函数,返回event_trigger类型
支持变量
- tg_event:为ddl_command_start、ddl_command_end、sql_drop之一。
- tg_tag:实际执行的DDL操作,如CREATE TABLE、DROP TABLE等
删除触发器
DROP EVENT TRIGGER [ IF EXISTS ] name [ CASCADE | RESTRICT ];6、游标编程
游标是一种临时的数据库对象,用来存放从数据库表中查询返回的数据行副本,提供了从包括多条数据记录的结果集中每次提取一条记录的机制,也为逐行处理数据库表中的数据提供了一种新的处理方法
1、声明游标变量
curVars1 recfcursor 不推荐使用,因为没有绑定查询语句
name CURSOR [ (arguments) ] FOR query其中,arguments是传入的参数,query是查询语句
2、打开游标
1、open for
OPEN unbound_cursor FOR query;用于未绑定的游标变量
2、open for execute
OPEN unbound_cursor FOR EXCUTE query-string;用于未绑定的游标变量,可以执行动态查询字符串
3、open bound_cursor
OPEN bound_cursor [ (argument_values) ];用于绑定的游标变量
3、使用游标
1、fetch
FETCH cursor INTO target;从游标中读取下一行记录的数据到目标中
2、close
CLOSE cursorName;刷题
1、is null判定,不能用 = null
2、where xxx [not] in xxx
3、left/right join 新的理解
4、执行顺序

5、union使用
6、if的使用,if(a,b,c),a成立则为b,否则为c
7、group_concat([distinct] 要连接的字段 [order by 排序字段 asc/desc] [separator ‘分隔符’])
8、left(字段,num)返回左边num个字符
9、substr(字段,first,end)返回第first到第end个字符
10、单表联查,select * from table as a,table as b
11、select distinct Salary from Employee order by Salary desc limit 1,1查找第二高的薪水
12、dateDiff(日期1,日期2) 返回日期1-日期2
13、A not in B的原理是拿A表值与B表值做是否不等的比较, 也就是a != b. 在sql中, null是缺失未知值而不是空值(详情请见MySQL reference).
当你判断任意值a != null时, 官方说, “You cannot use arithmetic comparison operators such as =, <, or <> to test for NULL”, 任何与null值的对比都将返回null. 因此返回结果为否,这点可以用代码 select if(1 = null, 'true', 'false')证实.
14、
case 语句: case when …. then … when … then … else …end as …
select id,
case when p_id is null then "Root"
when id in (select p_id from tree) then "Inner"
else "Leaf"
end as Type
from tree15、
sum(xxx),返回满足条件的总数



